Your AI agents finally remember.
Truenex Memory is the local memory layer that gives your AI coding agents persistent context. Instead of re-reading 60 docs every session (50,000+ tokens wasted), the agent queries and gets 5 relevant chunks. ~500 tokens. 0.3 seconds.
Based on Marco's current local multi-project store. Numbers vary by project size.

Core: Free. Forever.
Open source core (Apache 2.0). Single SQLite file, local embedder, zero model downloads. No cloud, no account, no subscription required for the open-source core. Optional Pro/Team features may come later without locking your local memory.
9 modular layers
From SQLite persistence to MCP server. Three-tier retrieval cascade. Source ledger state machine. Auto memory generation.
Four steps to give your agent a second brain.
From discovery to retrieval — once indexed, the agent never re-reads documentation again.
Discover
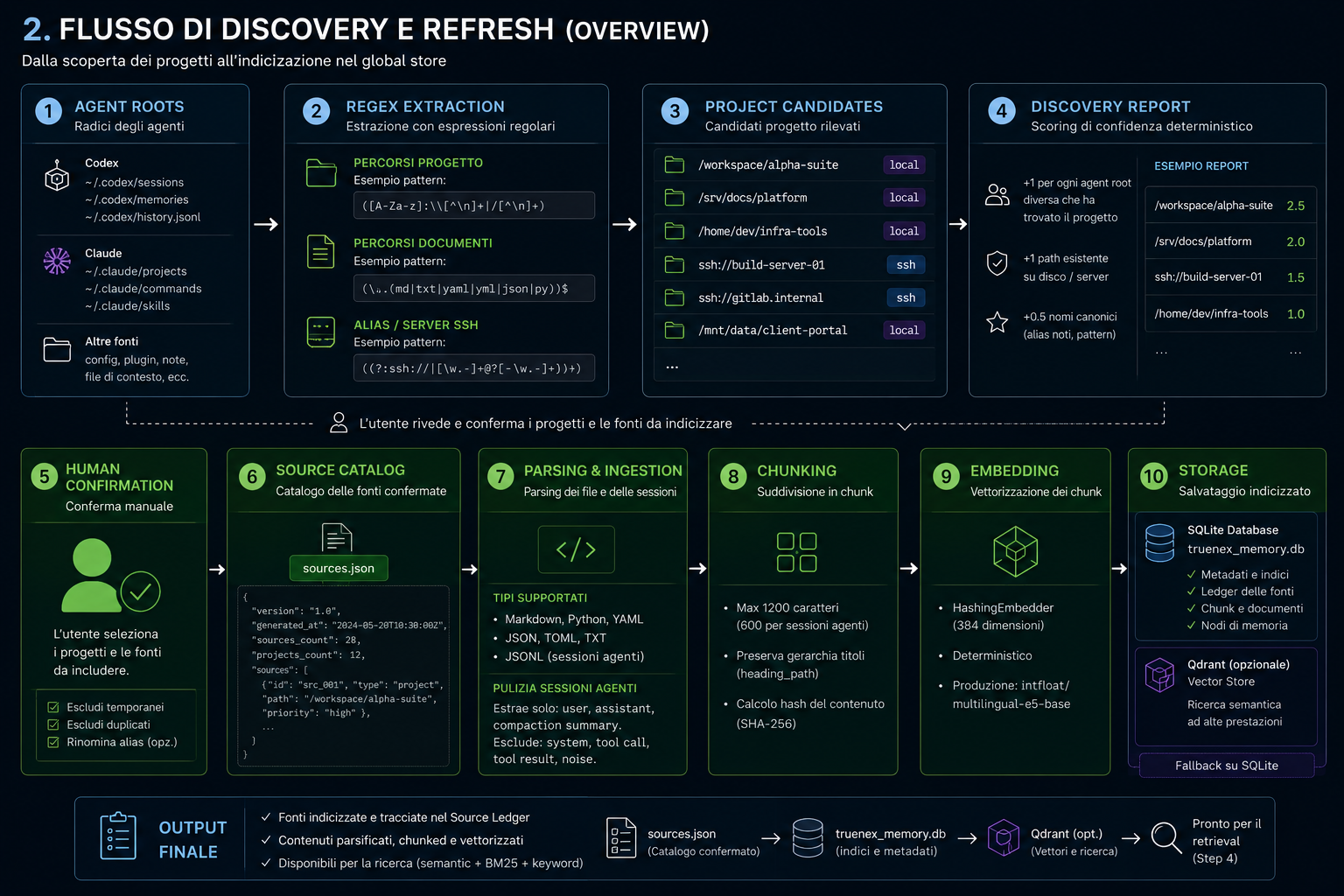
Scans .codex/ and .claude/ directories only. Finds projects, docs, SSH aliases. No blind disk scan.
Index
Markdown-aware chunking. 384-dim vector embeddings. Stored in SQLite. Once, then incremental updates only.
Query
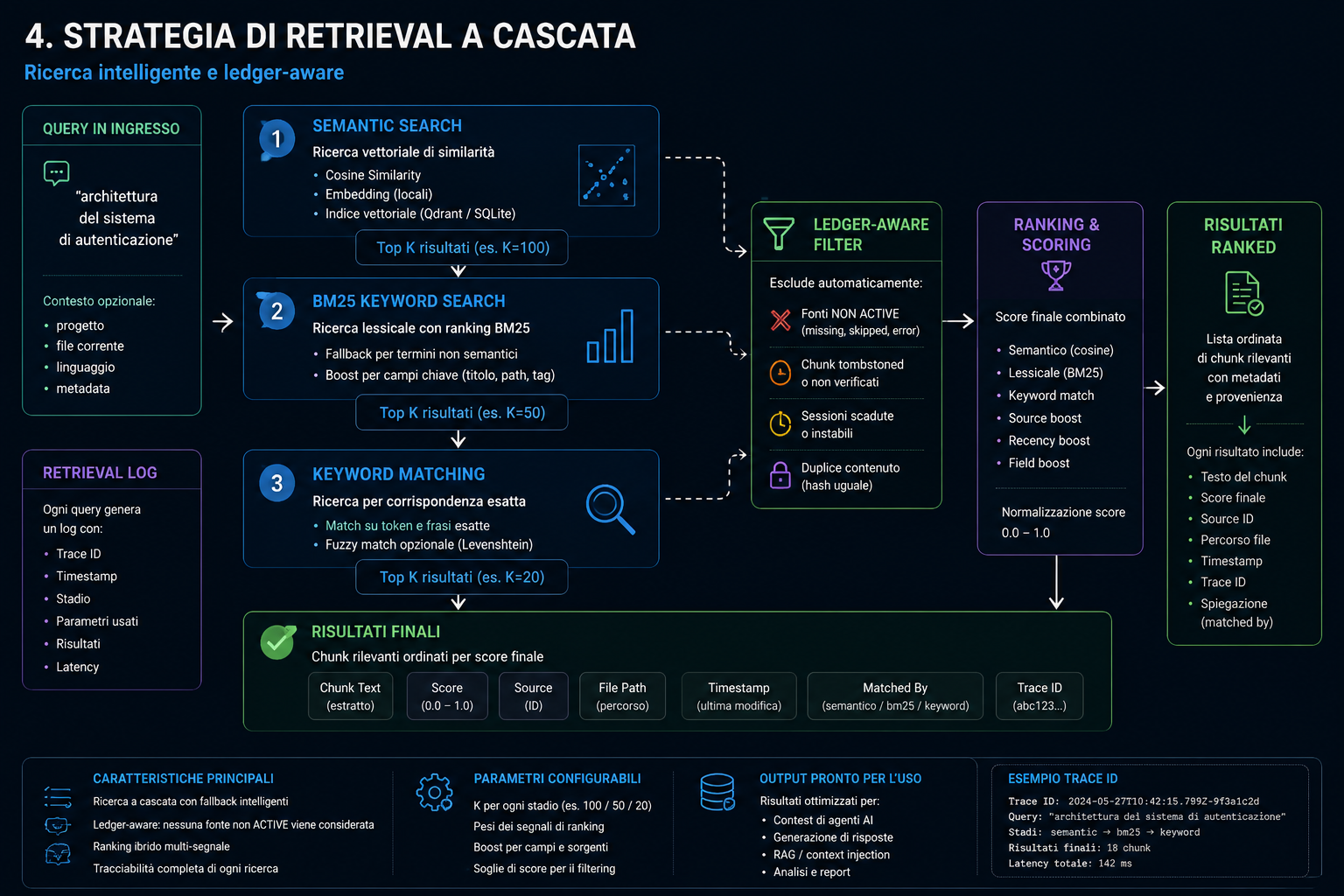
Agent calls memory_search(). Semantic → BM25 → keyword cascade. 5 relevant chunks in 0.3 seconds.
Learn
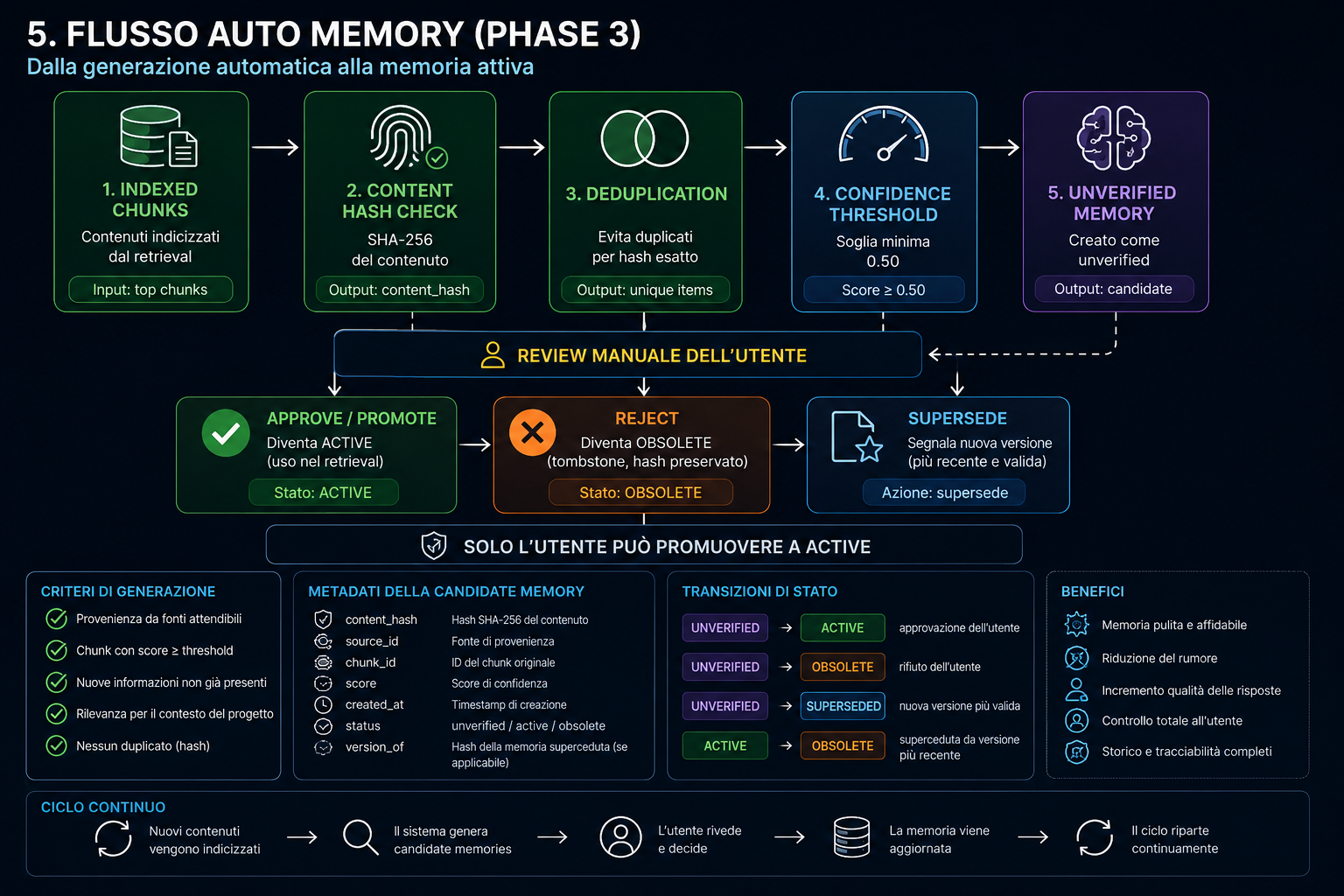
Generates conservative unverified memory candidates from indexed local sources. SHA-256 dedup and tombstone check. You review, approve, reject, or promote them into curated decisions, notes or patterns.

Your memory follows you. Not the other way around.
Most local AI memory tools trap your data on a single machine. Truenex Memory Pro breaks that lock with Git Bridge — sync your entire memory database across all your devices using any private Git repository.
Own Your Sync
Use GitHub, GitLab, Gitea, or your own server. Private repo, your rules, no cloud lock-in. Your data is exported as JSON and compressed with gzip — never a raw SQLite blob.
Zero Data Loss
Intelligent upsert (INSERT OR REPLACE) merges data without duplicates. Auto-repair fixes missing embeddings and UUIDs after every import. Your semantic search stays intact across devices.
Blazing Fast
Gzip compression shrinks exports from 118 MB to ~22 MB. SQLite PRAGMA optimizations and batch chunking make imports instantaneous. Sync takes seconds, not minutes.
Privacy Preserved
No third-party sync service. No telemetry. Your memory data travels only between your machines and your private Git repo. End-to-end control.
Stop paying for your agent's amnesia.
Every new chat session starts from zero. Your agent re-reads everything. That's 50,000 tokens you've already paid for, burned just to get back to where you were.
| Metric | Without Truenex Memory | With Truenex Memory |
|---|---|---|
| Docs read per session | 60+ files | 5 relevant chunks |
| Tokens wasted | 50,000+ per session | ~500 per query |
| Time to context | 2+ minutes | 0.3 seconds |
| Context Window | Saturated with noise | Free for reasoning |
| Persistence | Zero. Each session starts fresh. | Total. Persistent context across sessions. |

Nine layers. Zero bloat.
Each layer depends only on the ones below it. Modular, testable, tested on a real multi-project local store.
L1 · SQLite Database
Single file truenex_memory.db. 9 tables: documents, chunks, memory_nodes, edges, retrieval_logs, source_ledger, tasks, task_steps, verifier_rounds.
L2 · Ingestion Pipeline
Two parsers: text_docs (MD, PY, YAML, JSON, TOML) and jsonl_sessions. Session parser extracts only user requests, assistant responses, compaction summaries — excludes system messages and tool calls.
L3 · Chunking & Embedding
Markdown-aware deterministic chunking (max 1200 chars). HashingEmbedder at 384 dimensions. Zero model downloads. Qdrant optional with fails-closed fallback to SQLite.
L4 · Retrieval Engine
Three-tier cascade: Semantic (cosine similarity) → BM25 (keyword) → Jaccard token overlap. Ledger-aware: auto-excludes chunks from missing/skipped sources. Every query produces a RetrievalLog with trace_id.
L5 · Agent Discovery
External JSON manifest (~/.truenex-memory/agent_manifest.json) — no hardcoded paths. 8 agents pre-configured (Codex, Claude, Kimi, Cursor, OpenClaw, Aider, Antigravity, Gemini). Add, remove, or edit via CLI. Heuristic discovery finds new agents automatically.
L6 · Global Refresh
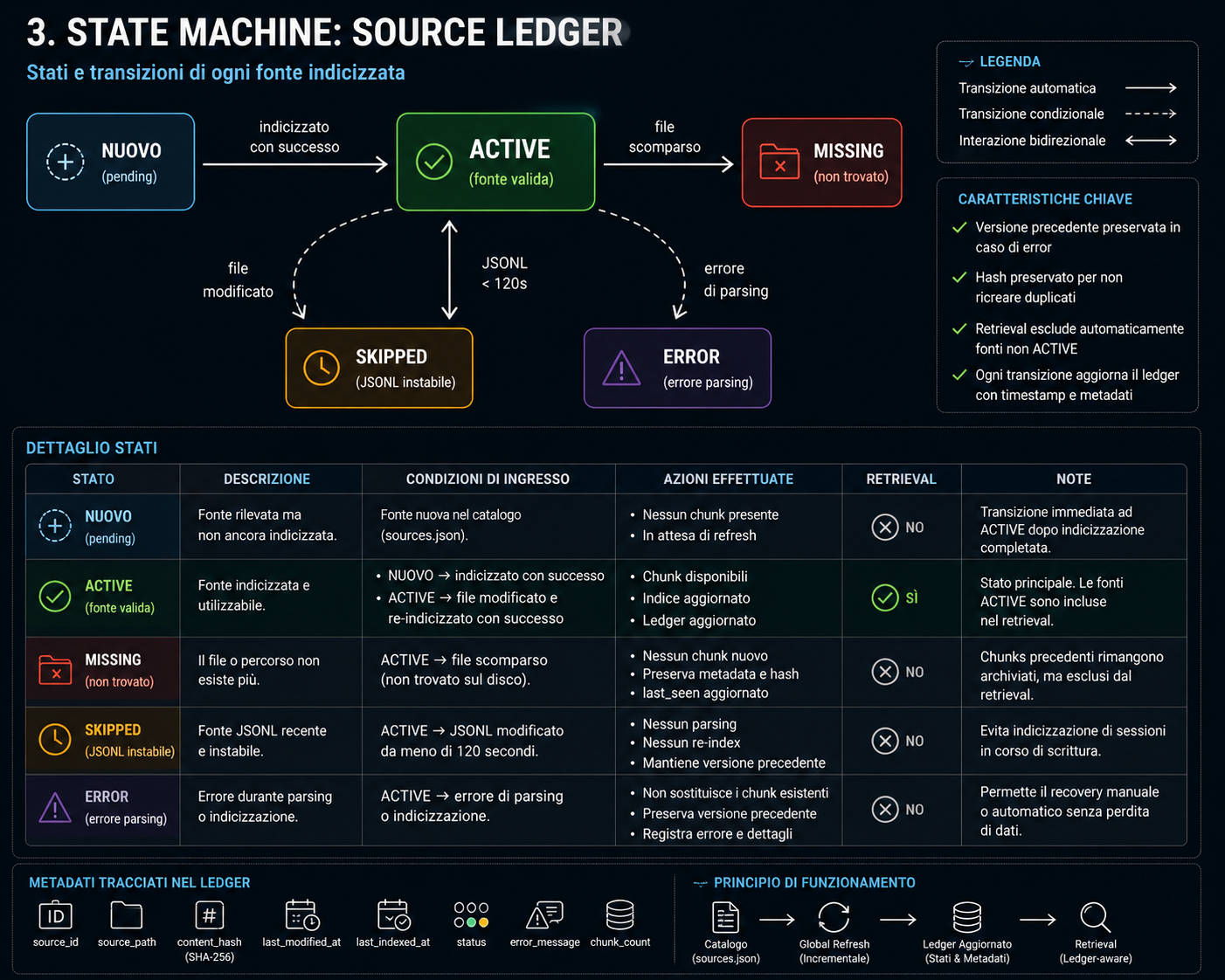
Incremental state machine. 5 states: pending → active ⇄ skipped | missing | error. Preserves last valid version on re-indexing error. JSONL stability check (120s configurable).
L7 · Auto Memory
Generates conservative unverified memory candidates from indexed chunks. SHA-256 dedup + tombstone check. Confidence threshold ≥ 0.50. Human review lifecycle: approve (active), reject (obsolete + tombstone), promote (curated_auto → decision / note / pattern).
L8 · MCP Server
JSON-RPC 2.0 over stdio. Tools: memory_search, memory_add, global_project_context, global_status, task_open/step_add/close. Native compatibility with Claude Code, Codex, Cursor.
L9 · CLI
Full command set: init, add, search, list, index, export, import, migrate, global discover/refresh/auto, doctor, mcp.

Retrieval Cascade
Built on three principles.
Local-First
Everything runs on your machine. Single SQLite file in your home directory. No GPU, no cloud, no API keys required. The embedder is deterministic — zero model downloads.
Privacy-First
Zero telemetry. Zero code or memory upload. Full JSON export — your data, always readable. If you stop using it, your data stays yours.
Agent-First
MCP stdio interface — the same protocol agents use to talk to the filesystem. Built for the agent, not for the browser. Native Claude Code, Codex, Cursor compatibility.

Three commands and you're live.
Install, initialize your project, and ask your codebase anything. Works on macOS, Linux, and Windows with Python 3.12+.
Using Claude, Kimi, Cursor, or Codex? Your AI agent can read this project memory automatically. Add truenex-mem mcp to your agent's MCP settings once. Setup guide →
Choose your tier.
Start free forever. Upgrade to Pro when you need advanced workflows and priority support.
- ✓Local SQLite memory
- ✓Full CLI (init, add, search, export...)
- ✓MCP server (Claude, Codex, Cursor)
- ✓Three-tier retrieval cascade
- ✓Source ledger & auto-memory
- ✓Apache 2.0, zero telemetry
- ✓Everything in Free
- ✓Git Bridge multi-PC sync
- ✓Advanced auto-memory workflows
- ✓Interactive knowledge dashboard
- ✓Cross-project search UI
- ✓Priority support
- ✓Future Pro features included
What's free, what may become paid.
The open source core is and will always be free. Optional Pro/Team features may add advanced workflows without ever locking your local data.
| Area | Open Source Core | Future Pro / Team |
|---|---|---|
| Local SQLite memory | Included | Included |
| CLI (init, add, search, export, etc.) | Included | Included |
| MCP for Claude Code, Codex, Cursor | Included | Included |
| Local search / retrieval cascade | Included | Included |
| Source catalog & ledger | Included | Included |
| Auto Memory review lifecycle | Included (manual review) | Advanced workflows |
| Visual graph / knowledge UI | Basic / deferred | Advanced UI |
| Multi-project dashboards | Basic CLI | Advanced UI |
| Multi-PC sync via Git Bridge | No | Included (Pro) |
| Team sync / shared memory | No | Optional, opt-in |
| Governance / audit / compliance | Local basics | Team / Enterprise |
| Cloud features | No | Optional, opt-in |
Your data is never locked
Full JSON export always available. If you stop using Truenex Memory, your data stays yours in a readable format.
Paid features improve workflows
Pro/Team features add convenience, not lock-in. They may add sync, governance, and advanced UI — never ownership of your memory.
Status: production on real store
Currently used on Marco's local store: 42k+ chunks, 7.6k+ documents, 95 confirmed sources. Public beta coming. No cloud features in core.
What Truenex Memory does NOT do.
Privacy isn't a feature. It's the architecture.
No secret scanning
Does not intentionally scan for secrets, tokens, or credentials. Discovery is confined to agent directories only.
No remote execution
Does not execute SSH commands, does not open remote databases. Server aliases in the catalog are hints only — no connection is made.
Zero telemetry
No analytics, no tracking, no phone-home. The embedder is deterministic — no model weights to download. The only network calls are those you explicitly configure.
No upload
Zero code or memory upload. All indexing happens locally. All embeddings stay on your machine. Full JSON export — readable by any tool.